머신러닝 시스템
이번 포스트에서는 머신러닝 시스템을 실제 서비스에 적용하는 문제에 대해 서술합니다. 내용은 머신러닝 실무 프로젝트의 4장 “기존 시스템에 머신런이 통합하기”을 참조합니다.
1. 학습과 예측
머신러닝 테크닉들을 보면 크게 학습(learning)과 예측(prediction or test) 두 단계로 구분됩니다. 학습은 학습데이터(여기서는 지도학습의 데이터와 타켓(label)이 합쳐진 데이터)를 사용하여 신경망 같은 알고리즘에 적용시켜 가중치를 학습하는 일을 나타내고 학습된 모델에 우리가 원하는 데이터를 적용시키는 것이 예측이라고 할 수 있습니다. 예를 들어보면 이미지분류를 위해 기존에 가진 이미지셋(학습 데이터셋)으로 분류기(모델)를 생성하는것이 학습이고 실제 사용자가 이미지 1장(데이터)을 업로드하여 어떤사진인지 분류하는 작업을 예측이라 할 수 있습니다. 머신러닝을 공부하다보면 이러한 요소들을 실제 서비스에 어떻게 적용하는지 고민을 할 수 밖에 없는데 이러한 요소들을 그림을 그리며 이해해봅시다.
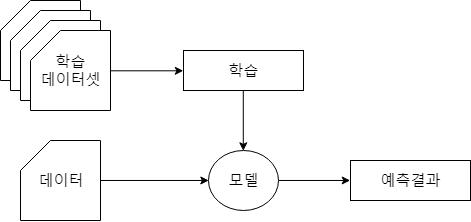
2. 배치와 실시간
위에서 머신러닝은 크게 학습과 예측단계로 구분된다고 하였습니다. 이것은 각각 배치(batch)와 실시간(real-time)으로 구분될 수 있습니다.
배치는 말그대로 어떠한 처리를 일괄적으로 하는것, 즉 task를 일정량 모아서 처리하는 것을 의미합니다. 실시간은 task가 발생하는 즉시 처리하는 것을 의미합니다. 예제를 통해 배치와 실시간을 이해해봅시다.
2.1 배치 학습
예를 들어 값 w_1 부터 w_100까지 100개가 존재하는데 이것의 평균을 배치(일괄)학습로 처리하면 다음과 같습니다.
sum = w_1 + w_2 + ... + w_100
w_result = sum / 100
w_1 부터 w_100 까지의 값을 더해서 100으로 나누면 우리가 원하는 평균을 구할 수 있습니다. 실시간(순차)학습은 다음과 같습니다.
2.2 실시간 학습
sum = 0
cnt = 0
while has_weight():
w_tmp = get_weight()
sum += w_tmp
cnt += 1
w_result = sum / cnt
처음부터 100개의 데이터가 존재하는 것이 아니라 데이터가 발생할때마다 평균을 구합니다. 이말은 즉 처음부터 100개의 데이터를 가지고 있는것이 아니라 처음에는 1개의 평균, 그 다음은 2개의 평균.. 그러다 결국 100개의 평균을 구한다고 할 수 있습니다.
이렇게 배치와 실시간을 비교해보면 학습도중 최적화하는 방법의 차이와 한 번에 다루는 데이터의 크기차이라고 할 수 있습니다.
3. 시스템 설계
그럼 시스템을 설계해 봅시다. 시스템설계를 위해 학습과 예측을 배치와 실시간의 조합으로 구성해야 합니다. 다음은 보통많이 사용되는 배치 학습과 실시간 또는 배치 예측의 조합과 실시간 학습으로 구성된 4가지 조합입니다.
- 배치 학습 + 실시간 예측(웹 어플리케이션)
- 배치 학습 + 실시간 예측(API)
- 배치 학습 + 배치 예측(DB)
- 실시간 학습
3.1 배치학습 + 실시간예측(웹 어플리케이션)
먼저 가장 간단한 시스템입니다. 우리가 만드는 웹어플리케이션에서 예측을 하는 함수를 만들어 특정 URL을 받으면 예측을 하고 예측결과를 출력하는 구조입니다. 모놀리식(monolithic)구조를 따르며 웹 어플리케이션과 같은 프로그래밍 언어를 써서 예측부분을 구현합니다. 이경우 예측의 결과가 실시간으로 반환되어야 합니다. 아니면 사용자 입장에서는 계속 로딩상태로 기다려야하기 때문이죠. 이를 위해 입력되는 데이터의 전처리, 특징 추출, 예측 모델 실행과 같은 요소들의 수행시간을 짧게 유지(시간복잡도가 낮고 공간 복잡도가 낮은 알고리즘들을 선택)하는것이 중요합니다.
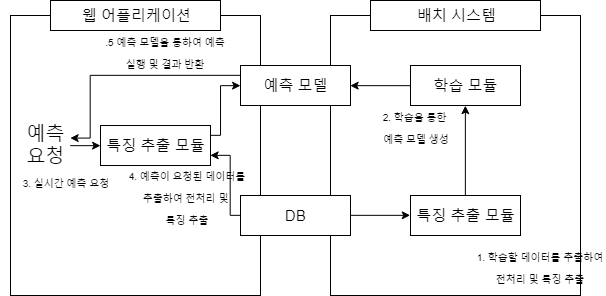
3.2 배치 학습 + 실시간 예측(API)
예측을 하는 시스템을 API로 분리하여 웹 어플리케이션과 따로 운영하는 방식입니다. API를 RESTful로 지원할수도 있고 여러개의 시스템과 연동하여 사용가능합니다.
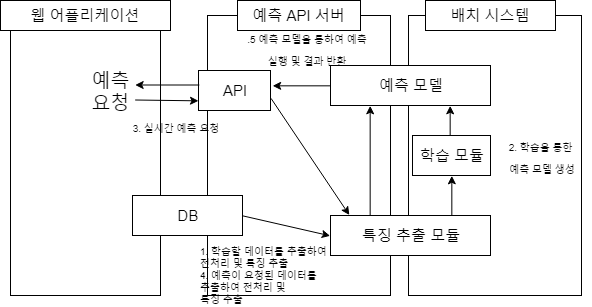
이 시스템은 웹 어플리케이션과 예측 서버의 언어를 다르게 구성할 수 있습니다. 예를 들면 웹 어플리케이션을 자바기반의 Spring으로 구현하고 예측 서버를 파이썬기반의 Flask로 만들어 연동 시킬 수 있습니다. 특히 클라우드를 사용할 시 웹 어플리케이션과 머신러닝을 각각의 서비스를 사용하여 구축한 뒤 이런식의 서비스 구조로 연동할 수 있습니다. 주의 할 점은 시스템간의 네크워크 지연이 길어질 수 있다는 점입니다.
3.3 배치 학습 + 배치 예측(DB)
웹에 적용하기 가장 유리한 시스템으로 일정 시간동안 쌓인 데이터에 대해 배치로 예측을 한후 다시 DB에 저장한는 구조입니다. 실시간이 아니므로 응답시간을 고려할 필요가 없고 웹 어플리케이션과 배치 시스템은 오직 DB만 공유하므로 두 번째 구조처럼 각각 다른 언어, 다른 프레임워크를 사용해서 개발이 가능합니다. 고려할 점은 학습과 예측의 배치 간격입니다. 데이터의 생성주기나 주기에 따른 생성 되는 데이터 크기를 바탕으로 간격을 결정합니다. 물론 학습간격이 예측간격보다는 깁니다.
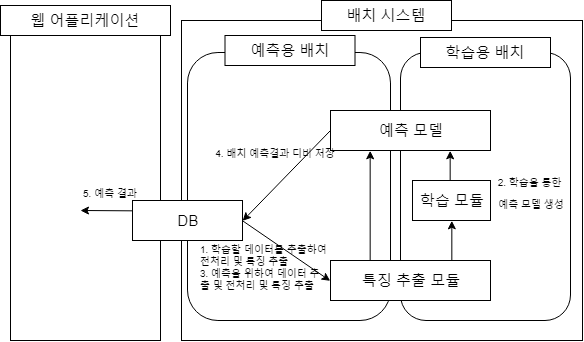
3.4 실시간 학습
실시간 학습은 흔히 사용되는 시스템은 아니지만 큐잉시스템(물론 이전 시스템들도 큐잉시스템을 도입할 수 있습니다)등을 조합하여 구현가능합니다. 카프카와 조합된 Oryx 프레임워크, 주파투스 프레임워크가 이러한 패턴을 염두해 설계되었습니다.
4. 각 방법의 특성
위 4가지 시스템 구조들의 특성은 다음과 같습니다.
| 패턴 | 배치학습 + 웹 어플리케이션 | 배치학습 + API서버 | 배치학습 + DB | 실시간 |
|---|---|---|---|---|
| 예측 시점 | 요청 시 | 요청 시 | 배치 | 요청 시 |
| 예측 결과 제공 경로 | 프로세스 내 API 경유 | REST API 경유 | 공유 DB 경유 | 메시지 큐 경유 |
| 예측 요청의 응답 지연시간 | O | O | O x 2 | O x 2 |
| 신규 데이터 추가부터 예측 결과 까지 걸리는 시간 | 짧음 | 짧음 | 짧음 | 짧음 |
| 한 건의 예측을 처리하는 시간 | 짧음 | 짧음 | 김 | 짧음 |
| 웹 어플리케이션과의 결합도 | 높음 | 낮음 | 낮음 | 낮음 |
| 두 시스템의 구현 언어 | 같음 | 무관 | 무관 | 무관 |
5. 결론
어떤 시스템을 선택해서 구현하는 정답은 없습니다. 필요에 따라, 상황에 따라 적절하게 시스템을 설계해야하는 것이 중요합니다.